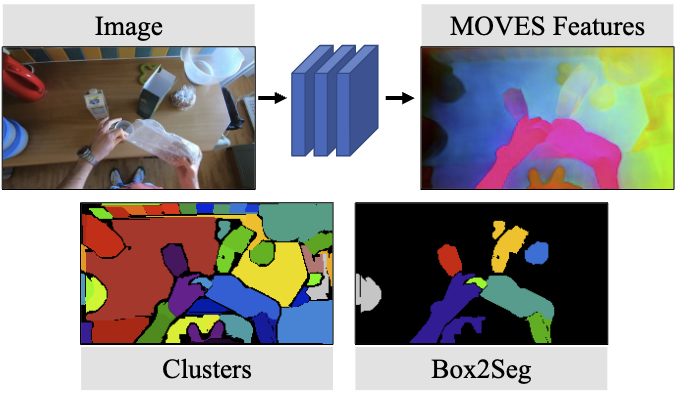
Given an input image, MOVES produces features (shown using PCA to project to RGB) that easily group with ordinary clustering systems and can also be used to associate hands with the objects they hold. The clusters are often sufficient for defining objects, but additional cues such as a box improve them further. At training time, MOVES learns this feature space from direct discriminative training on simple pseudo-labels. While MOVES learns only from objects that hands are actively holding (such as the semi-transparent bag), we show that it works well on inactive objects as well (such as the milk carton).
Abstract
Our method uses manipulation in video to learn to understand held-objects and hand-object contact. We train a system that takes a single RGB image and produces a pixel-embedding that can be used to answer grouping questions (do these two pixels go together) as well as hand-association questions (is this hand holding that pixel). Rather than painstakingly annotate segmentation masks, we observe people in realistic video data. We show that pairing epipolar geometry with modern optical flow produces simple and effective pseudo-labels for grouping. Given people segmentations, we can further associate pixels with hands to understand contact. Our system achieves competitive results on hand and hand-held object tasks.
Video
Method Overview

As input MOVES accepts an RGB image and produces a \(H \times W \times F\) per-pixel feature embedding using a backbone HRNET denoted \(f(\cdot)\). Pairs of F-dimensional embeddings from this backbone can be passed to lightweight MLPs \(g(\cdot)\) to assess grouping probability and \(a(\cdot)\) to identify hand association, or if the pixels are a hand and an object the hand is holding. Once trained, the MOVES embeddings (here visualized with PCA to map the feature dimension to RGB) can be used for:
- (Clusters) directly applying HDBSCAN to the embeddings produces a good oversegmentation;
- (Box2Seg): Given a box, one can produce a more accurate segment;
- (Hand Association) Applying \(a\) to a query point and every pixel produces hand-object association (here, to a drawer).
Results

Results from MOVES, with examples from the EPICK VISOR validation set.
- (Image) the input image;
- (MOVES Features) a PCA projection of the feature space to RGB;
- (Clusters) The clusters found by HDBSCAN applied to the feature space with each cluster visualized with a random color;
- (Association) The prediction of the association head on the image on one of the hands in the image;
- (Hands+Held) A Mask of hands and hand-held Objects in the image. The association head usually does a good job of recognizing the objects that hands are holding.
- (row 1) although the cabinet door is thin, MOVES recognizes the association between hand and door.
- (row 2) MOVES detects a large mixing bowl.
- (row 3) the transparent glass pan lid is recognized as an object by MOVES despite the stovetop below being visible through it.
- (row 4) the multi-colored hand towel is clustered as separate segments, however the association head helps segment most of the hand towel, showing the complementary nature of pairing an association head with clustering.
- (row 5) the transparent bottle is segmented nicely.
- (row 6) the cutting board is being cleared into the trashcan, but MOVES successfully identifies the board as being the held object.
Poster

Paper

MOVES: Manipulated Objects in Video Enable Segmentation
Richard E. L. Higgins and David F. Fouhey
In Computer Vision and Pattern Recognition, 2023.
@inproceedings{higgins2023moves,
title={MOVES: Manipulated Objects in Video Enable Segmentation},
author={Higgins, Richard EL and Fouhey, David F},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={6334--6343},
year={2023}
}Acknowledgements
This template was originally made by Phillip Isola and Richard Zhang for a colorful project, and inherits the modifications made by Jason Zhang. The code can be found here.